
Les environnements informatiques sont fondamentalement hétérogènes par nature d’abord parce que les capteurs et sources d’informations, systèmes (virtualisés) et personnes sont répartis partout sur le globe, mais aussi parce que l’évolution technologique est permanente et devrait se poursuivre.
Grâce à l’inexorable succès de Linux et des technologies ouvertes ‘open source’, le Cloud public est devenu une évidence et en même temps la quantité et la qualité des données a imposé une réalité : déplacer les données s’est vite avéré être à la fois coûteux et limité voire impossible.
Tout ne va pas passer par le siphon du Cloud public : passons en revue les stratégies hybrides, celles d’interfaces, de déploiements complets et via containers ; examinons, enfin, comment les approches de développement contribuent à l’agilité totale.
Hybride, vous avez dit Hybride ?
Le mouvement de fond fait que progressivement toutes les infrastructures deviennent des Clouds ou sont pilotées / interfacées comme tel. Une infrastructure IT fonctionnant avec les caractéristiques d’un Cloud permet de développer des solutions impossibles à créer sans ces caractéristiques.[1]
Donc dès que vous devez développer une application qui sera déployée dans le Cloud ou utilisera plusieurs modes de Cloud (public, privé), les outils que vous allez utiliser vont devoir vous permettre de résoudre les problèmes d’interopérabilité, de portabilité/accès aux données et de portabilité applicative dans votre infrastructure de déploiement hybride.
Mais revenons aux bases : lorsque l’équipe DevOps dispose des outils adéquats, le choix des modes de déploiement est d’abord fait en fonction de critères économiques. Or, dans les entreprises, ce sont des décisions financières (OPEX/CAPEX) ou stratégiques (ex : ‘ pas d’IT chez nous… ’ ou bien ‘ nos compétences sont élevées : nous réalisons notre Cloud ’…) qui vont déterminer les proportions d’IT en propriété (‘on premise’) / en location.
Qu’en est-il de la vague des APIs ?
Dans un environnement hybride, que ce soit dans des PME ou des grandes entreprises, les deux premiers problèmes à résoudre pour les applicatifs sont l’accès aux données et le test/déploiement.
Généralement, les données source sont dans des bases de données bien sécurisées : initialement le choix a été souvent fait de copier les données (avec quelques risques de sécurité), de les reformater, de les utiliser avec le nouvel applicatif et ensuite … chemin inverse. Beaucoup de développements reposent sur ce principe d’ETL (Extract, Transform, Load).
Après la vague ‘puriste’ SOA (Service-Oriented Architecture), la modularité et les besoins de flexibilité ont apporté les APIs (REST, JSON) plus simples à utiliser. Avec les APIs, sont apparus les outils permettant de découvrir[2] ces APIs, de les sécuriser et de les monétiser.[3] La gestion peut être faite soit en mode PaaS (dans IBM Cloud chez IBM), soit avec des ‘appliances’, soit avec des logiciels. Les APIs sont devenues un standard simple d’interopérabilité ; les développeurs qui les créent peuvent utiliser les technologies et systèmes de leur choix (et en changer ) afin de fournir les performances et accès nécessaires. Enfin, il est possible de composer les APIs entre elles pour développer de nouvelles APIs[4] !
Cette vague ‘API’ a atteint les développeurs « traditionnels » (Cobol…) qui mettent à disposition des APIs directement connectées dans les systèmes à la source des ETL. L’économie est grande : plus d’ETL et des performances impressionnantes sur des systèmes très rapidement adaptables (exemple : Walmart, qui fournit des APIs directement dans ses systèmes internes de type IBM z Systems - non pas dans des machines à base de processeurs Intel - et obtient en toutes circonstances des temps de réponses parfaits[5] : devineriez-vous en allant voir ce site que Walmart a une infrastructure backend faite de systèmes Intel, mais surtout OpenPower et IBM z Systems ?
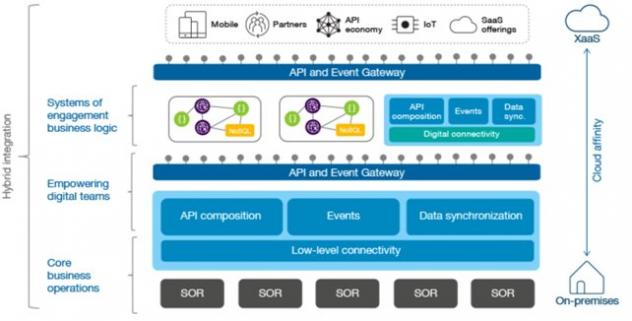
Le déploiement : principes et avantages
En même temps que les APIs, les outils open source de gestion de clouds (en particulier OpenStack[6]) sont devenus robustes et capables de déployer vers des domaines/clusters séparés et différents (divers types de systèmes et avec des binaires variés).
C’est un des avantages de LINUX : un OS et des méthodes/outils communs. Une application peut être créée et validée sur un laptop, dans un PaaS, et ensuite compilée puis testée/déployée/mise en production sur un système autre (par exemple : OpenPower avec des GPUs – processeurs graphiques[7] - , que ce soit dans un data center d’entreprise ou chez un CSP - Cloud Service Provider - comme Nimbix[8]. L’écosystème LINUX permet plus d’indépendance avec l’infrastructure (et il y a de nombreuses années qu’IBM l’a reconnu et supporte l’open source). Cela permet de déployer des applications ou parties d’applications sur les CPUs les plus adaptés : Intel, OpenPower (en intelligence artificielle[9], ARM, z Systems …) qui tous supportent Linux.
Ces standards ouverts sont clefs pour de vrais systèmes hybrides, et non pas des ‘on-prem’ ‘off-prem’ de systèmes propriétaires. VMware est également devenu membre de l’OpenStack et en utilise les interfaces : une application complexe développée à travers Windows, Linux, zOS et AIX peut être déployée depuis VMware.
Donc les outils de développements ouverts déployant sur des hyperviseurs ouverts sont ceux qui permettent d’avoir des déploiements vraiment hybrides, avec lesquels le développeur travaille sachant qu’il sera possible de sélectionner la plateforme physique de déploiement, ‘in fine’.
Donc…
- API : accès à distance de fonctions
- Déploiement : déploiement de machines virtuelles complètes (appli dans un OS)
… la dernière brique facilitant la flexibilité est celle de ne déployer qu’un petit bout (facile à déplacer/remplacer) … un container ..
L’importance des containers
Les APIs, combinées avec la virtualisation, les temps de transfert (d’immenses VMs avec appli et données à répliquer) et le besoin de modularité ont rendu très attractifs les déploiements qui utilisent des containers. Encore une technologie présente dans Linux depuis longtemps mais rendue vraiment simple à utiliser par Docker (et Kubernetes) et supportée sur tous les systèmes sous Linux, même sans un hyperviseur standard.
La popularité des méthodes agiles (et des organisations agiles[10]) est en train d’aider le mouvement afin d’obtenir des applications constituées de conglomérats de micro-services très modulaires. Quand on contemple ces galaxies d’applications monolytiques qui peu à peu sont remplacées par de nouvelles galaxies de services « containerisés », on réalise que la discipline de DevOps est essentielle pour éviter un chaos en opérations.
Mais clairement, on assiste à un Containaggedon : inévitable. On voit même des équipes IT mettre dans des containers des applications monolithiques afin de passer dans un environnement où toutes les modifications/additions futures vont être en containers (lors de l’OpenStack Summit en mai 2017 à Boston, Kubernetes est partout).
Et DevOps dans tout ça ?
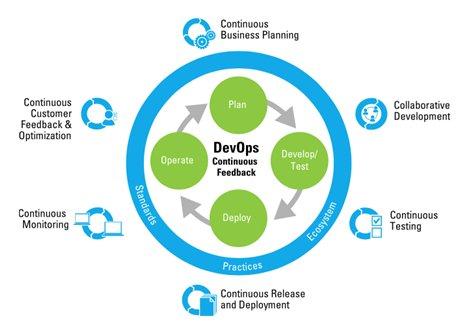
Les trois objectifs primaires de DevOps n’ont pas changé :
- La vitesse d’innovation (aidée par la collaboration du codage, via le test jusqu’à la production)
- La livraison d’application en continu (grâce aux outils d’automatisation)
- Le feedback par les outils de monitoring d’application
Et bien sûr cela ne fonctionne vraiment bien en mode hybride que si l’on supprime les frictions ‘aux limites’ : du code indépendant des plateformes et modes d’accès (LINUX), des outils communs/ouverts jusqu’au « template » de déploiement de la solution complète.
Le constat est là : tout le monde ne pourra pas assembler et maintenir des outils, le recours à des ensembles PaaS (« Platform as a Service ») tout prêts est donc inéluctable. Ceux-ci peuvent être partagés (Cloud toujours) ou privés (Cloud, locaux).
Encore une fois, pour tout cela, les outils open source (dont OpenStack) sont ceux qui offrent la plus grande hétérogénéité/flexibilité et garantissent une facilité de mouvement/déploiement en gérant toute la partie réelle de l’infrastructure – hyperviseur, OS, sécurité, stockage, réseau (et pour des containers aussi - ex : Mirantis, BlueBox) ou en mode PaaS (IBM Cloud).
L’avenir vous appartient !
Côté matériel, cela fait un moment que la loi de Moore est dépassée et que les machines sont devenues hybrides : GPUs, OpenCAPI, mémoire étendue dans des disques Flash…et cela ne va pas s’arrêter là. Cela va donner plus de possibilités.
Et il faut aussi penser au futur : il y a plus de chances que les outils ouverts survivent longtemps et que la communauté (toujours active) facilite les évolutions au cours du temps.
Coté logiciel, les évolutions récentes fonctionnent sur des systèmes hybrides (et des piles Open Source):
- noSQL (ex : MongoDB, EDB…)
- Bigdata (ex : Hadoop/Spark…)
- Deep Learning (ex : Tensorflow…)
- Blockchain (ex : Hyperledger fabric de la fondation Linux ...)
- Calculateurs quantiques (System Q, utilisable en Python)
En conclusion, gardez les yeux ouverts et l’esprit vif [11]: de même que vous attendez une tonalité lorsque vous décrochez votre téléphone (sans vous soucier de ce qu’il y a derrière), vos utilisateurs attendent de vous des applications capables d’évoluer dans les multiples infrastructures hybrides à votre disposition : il va vous appartenir de décider ce que vous mettez ‘derrière’ pour que vos utilisateurs soient satisfaits… et que vos solutions soient pérennes.
Eric Aquaronne, Responsable de la stratégie Cloud pour les plateformes matérielles IBM
[1] standards : http://nvlpubs.nist.gov/nistpubs/Legacy/SP/nistspecialpublication800-145.pdf , ISO/IEC 17788:2014, ISO/IEC 17789:2014).
[2] http://swagger.io/
[3] API ‘gateway’ ex : http://strongloop.com/node-js/api-gateway/
[4] http://www.Cloud-council.org et http://www.Cloud-council.org/deliverables/Cloud-customer-architecture-for-hybrid-integration.htm
[5] https://developer.walmart.com/#/home/
[6] https://www.openstack.org/
[7] https://openpowerfoundation.org/
[8] http://nimbix.com
[9] https://www.nextplatform.com/2016/04/06/inside-future-google-rackspace-power9-system/
[10] https://en..wikipedia.org/wiki/Conway's_law
[11] https://www.ibm.com/ibm/devops/us/en/resources/dummiesbooks/