
![]()
La startup Alkemics propose une plateforme de normalisation et d’enrichissement des données produits aux acteurs de la grande distribution. Grâce à cette solution, l’éditeur propose des services de moteur de recherche, substitution et recommandation basés sur la forte compréhension des données produits et des interactions des utilisateurs avec ces produits.
L’équipe technique regroupe des profils complémentaires :
- des profils orientés mathématiques appliquées et statistiques, pour le datamining et le machine learning,
- des profils très techniques sur les problématiques big data, notamment sur la gestion des infrastructures, bases de données et outils.
Algorithme et machine learning
Au coeur du fonctionnement de la plateforme Alkemics, nous trouvons des algorithmes de Traitement du langage (NLP) et du Machine Learning (ML) pour traiter les importants volumes de données produits et utilisateurs. L’approche est basée sur l'utilisation d'un graphe sémantique pour représenter à la fois les produits, les utilisateurs et surtout les relations qui les lient.
L'utilisation d'un graphe, à la fois pour le modèle de données et son implémentation permet d'avoir une vision très limpide des relations. Le marketing est avant tout une histoire de relations, cette approche est donc particulièrement pertinente pour les clients.

Ce graphe est mis à disposition des marques en tant que plateforme SaaS, les besoins en capacité de traitement des requêtes évoluent donc au gré des campagnes marketing de ces utilisateurs, d'où la nécessité d'une infrastructure Cloud.
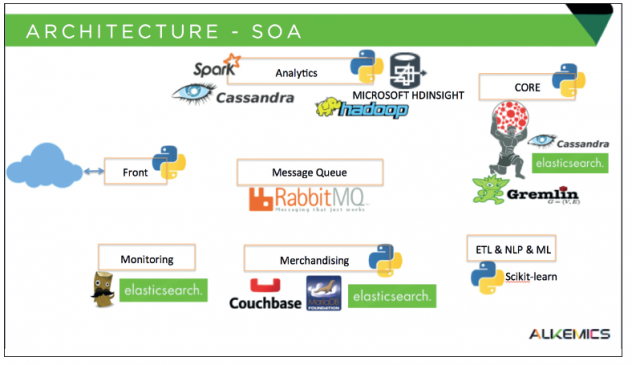
Comment ça marche ?
L’infrastructure de production est une architecture orientée services, constituée d'une cinquantaine de composants, communiquant grâce à un broker RabbitMQ et des requêtes HTTP. Cette architecture permet beaucoup de flexibilité en termes de choix technologiques pour l'implémentation du back-end. Alkemics a pu ainsi choisir et faire évoluer chacun des services indépendamment les uns des autres pour répondre au mieux aux besoins de développement. Cette architecture a l’avantage de permettre d’adapter dynamiquement les ressources pour chacun des services sollicités, pour mieux répondre aux besoins réels de traitement. C’est la flexibilité du Cloud.
La plupart des services sont historiquement écrits en Python. En effet, l'utilisation de Python donne accès à de très nombreuses librairies open source (ntlk, scikit-learn, scipy, numpy) pour le traitement du langage naturel et le Machine Learning. À mesure que la plateforme évolue, les équipes techniques intègrent de plus en plus de composants Go, pour les microservices et en Scala pour interagir avec Spark. Les APIs sont exposées en HTTP via des serveurs Web nginx ou en AMQP via RabbitMQ.
Ces services communiquent avec des backends variés en fonction des besoins :
- Couchbase pour les vues matérialisées et le cache distribué, primordial pour conserver les performances raisonnables alors que la volumétrie de données augmente,
- ElasticSearch pour les moteurs de recherche,
- Cassandra pour le stockage de timeseries d'analytics, les vues matérialisées de matrices pour la recommandation, un event store pour les événements générés sur notre plateforme et le backend de stockage pour l'ensemble des informations normalisées d'interactions des utilisateurs.
En particulier, la brique Core est constituée essentiellement de Titan, une base Graphe distribuée construite sur un backend de stockage Cassandra et un backend d'indexation ElasticSearch. L'utilisation du graphe donne une flexibilité extrême en termes de modèle de données tout en permettant des requêtes normalisées. Pour des raisons de performance, la R&D étudie depuis peu la possibilité d'utiliser GraphX sur un cluster Spark+Cassandra.
Enfin, le pipeline d'analytics est constitué jobs PIG qui sont exécutés sur un cluster HDinsight (solution Hadoop-as-a-service disponible sur Azure). Les données préprocessées sont alors ingérées dans Cassandra pour le reporting, les analytics le datamining interactif.
Cette utilisation d'un cluster hadoop-as-aservice permet de prétraiter et filtrer les forts volumes de données reçus de manière complètement scalable et en temps constant, sans nécessiter la maintenance d'un cluster en permanence.
Quotidiennement, le cluster HDInsight est créé et détruit. Il est utilisé environ 3h pour effectuer les traitements batch sur les données.
La plateforme permet aux marques de contribuer à l'enrichissement des fiches de leurs produits sur les sites des distributeurs.
Cet enrichissement servira alors à améliorer l'expérience utilisateur sur le site d'ecommerce : fiches produits détaillées (images, labels de qualité, valeurs nutritionnelles, etc...), plus grande pertinence des résultats des moteurs de recherche et des recommandations.
Le processus d'échange peut être automatique ou manuel selon la maturité des systèmes d'information des marques.
Par exemple, nous mettons à disposition un portail web sur lequel les marques peuvent se connecter pour procéder aux échanges. Nous leur proposons alors d'importer les données déjà présentes dans leurs bases de données dans les formats standards GS1 d'échange de données produit.
Une fois un premier import effectué, nous permettons aux marques d'enrichir la donnée initiale avec les éléments obligatoires pour les distributeurs ainsi qu'avec des informations marketing afin de mieux mettre en valeur leurs produits : visuels, labels et certifications, histoire du produit, etc...
La marque peut alors déclencher le transfert de ses fiches au distributeur. Une fois cette étape effectuée, les données brutes sont normalisées par nos algorithmes de façon à les rendre exploitables par nos APIs.
Nous transmettons alors les données brutes aux distributeurs pour alimenter leur base produit et utilisons les attributs normalisés pour faire fonctionner nos webservices (moteur de recherche, substitution, etc...).
Ressources
- Partitioning sur graphe :
http://www.cs.utexas.edu/users/inderjit/public_papers/kdd_bipartite.pdf
- Partitioning (papier payant) :
http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.4.8969
- Mapreduce sur titan :
http://s3.thinkaurelius.com/docs/titan/0.5.2/hadoop-performancetuning.html#d0e14203
- Graphx (papier) :
https://amplab.cs.berkeley.edu/wp-content/uploads/2013/05/gradesgraphx_with_fonts.pdf
- Faire de la théorie des graphes de manière scalable sur un property graph :
https://www.kent.edu/sites/default/files/TR-KSU-CS-2010-01.pdf
- Recommandation de tags par graph ranking :
http://www.researchgate.net/publication/221300417_Personalized_tag_recommendation_using_graphbased_ranking_on_multi-type_interrelated_objects/file/60b7d521eb53e9d537.pdf
Startups ! Rejoignez gratuitement Bizspark et bénéficiez de 4 175€ de crédit Microsoft Azure