
DevFest Toulouse 2016 : retour sur la première édition du festival de développeurs toulousains
mar, 06/12/2016 - 12:07
Le 3 novembre 2016 se tenait à l’IUT de Blagnac la première édition du DevFest Toulousain. Le DevFest, c’est 22 conférences, réparties sur quatre tracks parallèles : mobile, web, outils et data/cloud.
BigQuery, Web VR, Angular, React, TensorFlow, Cloud Analytics, NativeScript, Polymerfire, Progressive Web Apps... Les thèmes sont variés et les 300 participants construisent leur programme en circulant entre les trois salles mises à disposition pour l’événement. L’ensemble est rythmé par l’énergie communicative des bénévoles et des speakers.
Petit retour sur une journée de veille condensée !
9h - Keynote d'ouverture : “Évolution du métier de développeur ces dernières années.”
Alex Danvy - Microsoft, France (voir les slides)
Mention spéciale pour la keynote d’ouverture qui a donné le ton de l’événement. Sus au cliché du développeur barbu qui se nourrit des miettes de pizza retrouvées entre les touches de son clavier ! La communauté de développeurs est représentée ici par l’envie de partager son expérience, d’apprendre de celle des autres, et de trouver toujours de meilleures solutions en mobilisant une palette d’outils qui évoluent à la vitesse de l’éclair. C’est aussi la volonté d’inclure tous les profils, à l’image de l’initiative Duchess France qui œuvre pour le renforcement des rangs de développeuses en encourageant les juniors. Leave No Newbie Behind!

10h - De Angular à React (ou pas)
Gilles Debunne - Freelance, France
Après avoir mené plusieurs projets sous Angular 1, Gilles Debunne peut enfin dire qu’il maîtrise le sujet. Il décide donc, en toute logique, de laisser de côté Angular et de choisir React pour son nouveau projet. Pourquoi ? D’une part, parce que Angular 2 ne semble pas séduire les foules. D’autre part, parce que React, lui, a déjà une communauté de fervents défenseurs et semble offrir des possibilités intéressantes. Et surtout, pour le plaisir d’apprendre et de découvrir une nouvelle technologie ! Ce talk a été l’un de mes préférés de la journée. L’heure est passée vite (surement aussi parce que j’étais encore fraîchement réveillée) et, même si je ne maîtrise encore aucune de ces deux technologies, j’ai pu tirer des enseignements de leur comparaison point par point. Bien joué à Gilles Debunne qui est parvenu à rendre l’ensemble pertinent pour des connaisseurs, et abordable pour les curieux néophytes comme moi.
10h - Clean Code
Antoine Vernois - Crafting Labs, France (voir les slides)
Antoine Vernois nous vient dans un but noble : nous aider à produire du code clean. L'intention est là mais la tâche est ardue.
Le verdict est sans appel, le Quick'n Dirty n'est clairement pas une bonne idée. Le meilleur moyen de faire rapide est de coder proprement. Fini les fix rapides qui explosent de partout. Quelques principes fondamentaux : extraire les détails pour plus de lisibilité, ne pas hésiter à utiliser des noms de variables et fonctions explicites, ne pas hésiter à créer des tests car ils donnent la confiance pour modifier le code, et enfin, les commentaires ne sont pas toujours judicieux car le code doit être compréhensible sans.
Car au fond, qu'est-ce qu'un code clean ? Le speaker nous expose sa vision clairvoyante. Un code clean, c'est un code lisible, sans acronyme, refactorisé, et surtout testé. Back to Basics. Avec sa conférence à la fois accessible aux débutants mais pleine de bons conseils même pour les confirmés, il nous a régalés.

10h50 - Dans les coulisses de Google BigQuery
Aurélie Vache - ATCHIK, France (voir les slides)
Pour ce talk, Aurélie Vache laisse de côté ses casquettes d’organisatrice de la journée, de Duchess France Leader et de marraine de la promotion #2 de Simplon, pour revêtir celle de Lead Developer chez Atchik. Au programme : retour d’expérience sur le passage pour l’entreprise du Cluster Hadoop à la solution Google BigQuery. Résultat des courses : 12 serveurs physiques remplacés par une solution dématérialisée, une diminution significative des coûts et un boost non négligeable au niveau des performances. Pendant la présentation, Aurélie nous fait une démonstration de l’outil, qui permet de bien se rendre compte de la vitesse impressionnante à laquelle il peut traiter un grand (très grand) nombre de données.

10h50 - WebVR : de la réalité virtuelle dans nos navigateurs, en route vers le Metaverse !
Olivier Guillet - Emotic, France (voir les slides)
Pour cette conférence, Olivier Guillet nous invite dans le web de la Réalité Virtuelle. Cette technologie plutôt récente nous permet d'utiliser la VR à l'intérieur même de nos navigateurs. Pour l'instant, elle est très utilisée sur la plateforme de Youtube 360 pour du contenu sportif et sur Steam où le jeu vidéo est roi. On y apprend que W3C développe actuellement une API qui a pour vocation d'être compatible avec tous les navigateurs et tous les casques de réalité virtuelle. Le Web VR intéresse de plus en plus, même Facebook va s'y lancer. On pourra bientôt créer notre avatar et l'amener de monde virtuel en monde virtuel, au gré de nos envies.
Le futur ? Une VR non plus bridée à 60fps (images par seconde) sur navigateur mais maintenant accessible à 90fps et une nouvelle version plus officielle de WebGL, la technologie qui ouvre les portes de la VR aux navigateurs.
11h40 - Don't call me just a website anymore. I am a progressive web app
Olivier Leplus - Google, France (voir les slides)
Comment développer pour mobile en 2016 ? Olivier Leplus commence sa présentation par une analyse des forces et faiblesses des solutions les plus utilisées actuellement : applications natives et hybrides, ou sites web responsive. Là où les applications natives et hybrides offrent des possibilités plus poussées (meilleure expérience utilisateur, accessibilité hors ligne, utilisation des fonctionnalités du téléphone...), les sites web responsives ont l’avantage d’être directement accessibles depuis n’importe quel navigateur et sont plus faciles à mettre à jour. Si la tendance est aujourd’hui aux applications natives, selon Olivier Leplus celle-ci risque de vite s’inverser.
Il illustre cette idée en remontant dans le temps : vous vous souvenez de l’époque des applications natives desktop et de ce bon vieux CD d’Encarta ? Balayé par le web et Wikipédia. Alors, si le mobile suit la même tendance, comment combiner le meilleur des applications natives et du web ? Réponse proposée ici : la progressive web app. Entre site web et application native, elle propose de nombreuses fonctionnalités : installation pour une utilisation hors-ligne, notifications push… J’ai trouvé la présentation très claire et bien détaillée autour des caractéristiques attribuées aux progressive web apps.

14h - Wanna more fire? - Let's try polymerfire!
Sofiya Huts - JustAnswer.com, Ukraine (voir les slides)
Les petits fours du midi étaient bons, très bons, trop bons sûrement. Ma capacité de concentration n’est plus celle de 9h ce matin. La présentation de Sofiya Huts semble pourtant très claire. Elle décrit, étape par étape, la méthodologie qu’elle a mis en place pour créer une progressive web app en associant Polymer (librairie de composants web open-source de Google) et Firebase (framework de Google pour stocker et manipuler les données en temps réel). La combinaison de ces deux outils permet de créer des applications rapidement, en se concentrant sur la partie front-end.

14h50 - Tensorflow et l’apprentissage profond, sans les équations différentielles
Martin Gorner - Google, France (voir les slides)
J’ai longtemps hésité avant d’aller voir cette présentation, tiraillée entre mon envie d’en savoir plus sur le machine learning et la crainte de ne pas avoir le bagage nécessaire en notions mathématiques pour comprendre le sujet. Verdict : Aoutch. Difficile de faire un retour constructif sur ce talk, alors que j’étais déjà complètement perdue passée la slide d’introduction. Toutefois, une fois acceptée la dure réalité (non, un niveau bac en maths ne suffit étonnamment pas à saisir toutes les subtilités de l’intelligence artificielle), j’ai fini par me prendre au jeu. Martin Gorner a réussi à rendre son talk vivant en expliquant comment relever le défi de faire reconnaître l’écriture manuscrite à une machine en mobilisant Python, Tensorflow, des trucs d’ingénieur et visiblement un peu de magie noire.

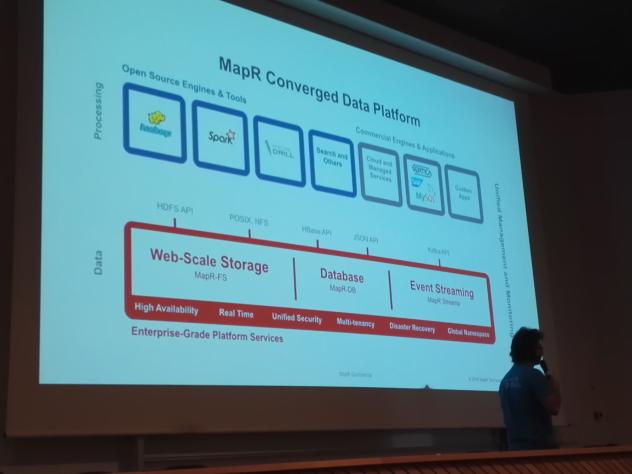
16h00 - Fast Cars, Big Data - Ou comment le streaming peut aider la Formule 1!
Tugdual Grall - MapR France (voir les slides)
Avec son talk Fast Cars, Big data, Tugdual Grall s’est proposé de nous expliquer, à quoi servent les données dans la formule 1 et comment elles sont utilisées, le tout à base de démonstrations.
Dans les paddocks, une multitude d’informations sont recueillies pour aider les pilotes et les techniciens : vitesse, tour par minute, utilisation des freins, des roues... Chaque voiture regroupe à elle seule près de 300 capteurs, les données sont envoyées sur 2000 canaux différents et parviennent au paddock dans les 2msec. Au total ce sont 1,5 milliards de points qui sont capturés pour une même formule 1 soit 5/6 go de données en 1H30 de courses.
Toutes ces données sont analysées en temps réel mais aussi beaucoup après les compétitions. L’idée étant de pouvoir capter le maximum d’informations et d’en suivre l’évolution pour prévoir la réaction de la voiture, du pilote...
Le but ici était d'analyser ces données avec différents outils comme dans la démonstration présentée avec le simulateur de course, TORCS race simulator. Dans cette démo, les données sont envoyées sur une techno de streaming, qui les affiche dans un dashboard, et sauve les données dans une base de données.
Ce talk m’aura permis de découvrir les technos : Kafka (projet opensource créé par Linkedin : techno de streaming pour déplacer de la donnée) et MapR Streams (même concept que Kafka, système de flux de données) qui permettent de faire le lien entre les producteurs de données et ceux qui les analysent, le tout en temps réel avec une échelle illimitée.
Avis aux curieux, la démo de TORCS est disponible sur Github (démo). Elle peut être regardée et est utilisable mais le simulateur n’envoie pas beaucoup de données dixit notre talker.
Talk très intéressant, surtout pour découvrir Kafka et MapR Streams ainsi que la gestion de gros volumes de données en temps réel via le streaming.
16h50 - My resumé in an operating system : un buzz et ses conséquences
Mathieu Passenaud, France (voir les slides)
Mathieu Passenaud fait le bilan du buzz involontaire qu’il a provoqué (subi ?) en publiant un jour un article sur son blog perso, expliquant comment créer son CV en système d’exploitation. L’idée n’était pas tout à fait nouvelle, le blog n’était pas spécialement connu mais Internet a fait son œuvre et un effet boule de neige a propulsé Mathieu dans le top 5 de hacker news. Résultat : 240 000 vues en 2 jours, un serveur fait-maison qui brûle, et quelques offres d’emplois pour le moins intéressantes. L’ensemble est présenté sans prétention : un bon talk pour finir la journée sur un ton un peu plus léger !
17:45 - Clôture du DevFest Toulouse 2016
L’occasion de faire le bilan de cette journée : c’était dense, la fatigue se fait sentir, mais nous avons le sentiment d’en savoir plus sur un éventail complet de sujets. Bon point pour l’organisation, surtout pour une première édition : un programme intéressant, un déroulé souple, des goodies sympas, un bon traiteur, et surtout une énergie communicative qui fait chaud au cœur !


Pour revenir sur l’édition 2016, retrouvez les slides des speakers répertoriés ici : https://docs.google.com/spreadsheets/d/1ZDfEUXTmGSTgzjuZo6_pjkXCwsDyZlf37jMFblEzuUs/edit#gid=0 [1]
Et pour ne rien rater de la préparation du DevFest Toulousain de 2017, rendez-vous sur Twitter @DevFestToulouse !
Juliane Blier, Marine Colonge, Laure Milian
Apprenantes Simplon Toulouse #2
Développeuses Web