
Réduire l’empreinte des vecteurs : la quantification vectorielle partie 1
mer, 08/01/2025 - 07:22
Dossier de Han HELOIR, EMEA Gen AI Solutions Architect (MongoDB)
Introduction : la révolution des embeddings et ses défis cachés
L’intelligence artificielle générative, notamment à travers le Retrieval-Augmented Generation (RAG), révolutionne la gestion des données en combinant la puissance des modèles génératifs avec des bases de connaissances structurées. Cette approche permet d’automatiser des tâches complexes tout en accédant en temps réel à des informations précises et pertinentes provenant de multiples sources.
Au cœur de ces systèmes se trouvent les embeddings, des vecteurs mathématiques capables de représenter des données non structurées telles que des textes, des images, ou des vidéos. Ces vecteurs permettent de réaliser des tâches avancées comme les recherches sémantiques, les recommandations, ou encore l’analyse de similarité.
Cependant, derrière l’innovation se cache une complexité technique. Lors de la phase de PoC (Proof of Concept), la gestion des embeddings peut sembler relativement simple. Mais une fois en production, ces vecteurs deviennent une source importante de coûts, de latence, et de problèmes d’évolutivité. En effet, leur stockage, leur traitement, et leur recherche à grande échelle exigent des infrastructures coûteuses et complexes.
Dans cet article, nous explorons comment la quantification vectorielle, associée à des techniques de l’indexation comme HNSW(Hierarchical Navigable Small World), peut réduire significativement ces obstacles. Ces approches permettent de maintenir des performances élevées tout en rendant la scalabilité plus accessible.
Les défis techniques des embeddings en production
1. Explosion des coûts de stockage
Chaque embedding est une représentation numérique haute dimension, souvent en format float32. Cela signifie que chaque élément du vecteur utilise 32 bits de mémoire. Multipliez cela par des millions, voire des milliards d’embeddings, et vous obtenez des volumes de données astronomiques.
Prenons un exemple concret : une base contenant 250 millions d’embeddings, chacun ayant 1 024 dimensions. En format float32, cette base occuperait 7,5 To d’espace et coûterait environ 3 600 $ par mois sur une plateforme comme AWS. À cela s’ajoutent les frais pour les sauvegardes, la redondance, et la haute disponibilité. Ces coûts deviennent rapidement prohibitifs, notamment pour des start-ups ou des projets avec des budgets limités.
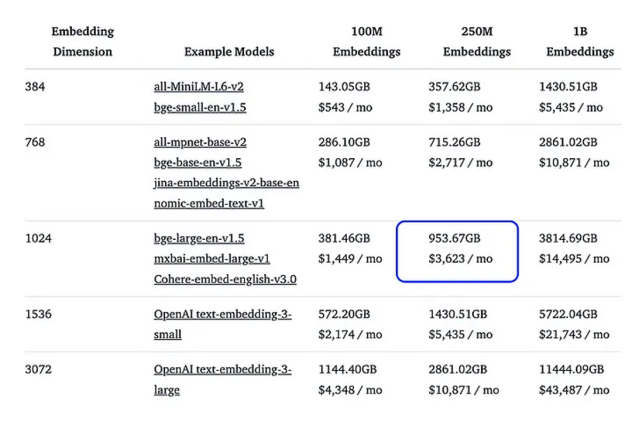
Embeddings et le coût associé (Source: HuggingFace)
2. Latence accrue et surcharge computationnelle
Les embeddings ne se limitent pas au stockage ; ils doivent également être interrogés pour effectuer des recherches rapides et précises. Ces recherches, appelées recherches de voisins les plus proches (Nearest Neighbor Search), nécessitent des calculs dans des espaces vectoriels de haute dimension. Chaque vecteur doit être comparé à d’autres pour déterminer les éléments les plus similaires.
Plus les vecteurs sont longs (haute dimension) et plus la base de données est volumineuse, plus la recherche devient longue. Cela pose un problème critique dans les applications en temps réel, où les utilisateurs s’attendent à des réponses quasi instantanées. Par exemple, une application de recommandations doit répondre en moins de 300 millisecondes pour maintenir une expérience utilisateur satisfaisante. Une recherche trop lente peut entraîner une frustration des utilisateurs et une perte de clients.
3. Scalabilité limitée
À mesure que le nombre d’utilisateurs et de données augmente, les exigences en calcul et en mémoire explosent. Cela entraîne des frais supplémentaires en matériel (serveurs, RAM) et en infrastructure cloud, créant un goulot d’étranglement financier. Les entreprises sont alors confrontées à un dilemme : réduire la qualité du service ou augmenter leurs dépenses.
HNSW : Une indexation intelligente pour les recherches rapides
1. Une structure hiérarchique
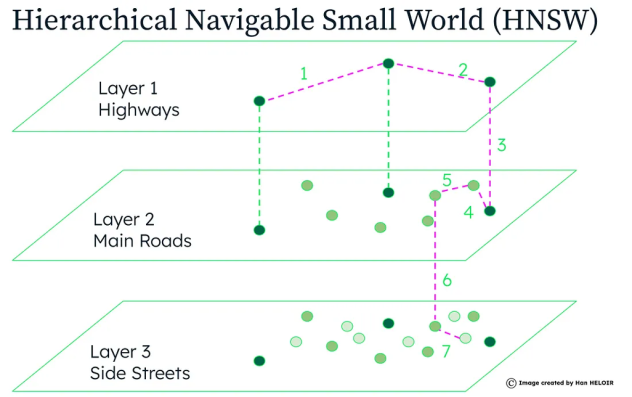
HNSW (Hierarchical Navigable Small World) est une méthode d’indexation conçue pour accélérer les recherches dans des bases vectorielles. Contrairement à une recherche linéaire, qui comparerait chaque vecteur à l’ensemble des autres, HNSW construit un graphe multi-niveaux pour organiser les données de manière plus efficace.
Ce graphe hiérarchique fonctionne comme une carte routière :
- Niveau supérieur : Les autoroutes, qui permettent de parcourir rapidement de grandes distances.
- Niveaux intermédiaires : Les routes principales, qui affinent la recherche.
- Niveau le plus bas : Les petites rues, qui mènent aux résultats finaux.
En utilisant cette approche, HNSW réduit drastiquement le nombre de comparaisons nécessaires pour trouver les voisins les plus proches d’un vecteur, tout en garantissant une recherche rapide et précise.
2. Avantages et limitations
HNSW est particulièrement efficace car il :
- Réduit les temps de recherche, même dans des bases massives.
- Permet des mises à jour incrémentielles (ajout de nouveaux vecteurs sans reconstruire tout l’index).
Cependant, cette méthode exige une grande quantité de RAM, car le graphe doit être entièrement chargé en mémoire pour offrir des performances optimales. C’est ici que la quantification vectorielle devient essentielle, car elle réduit la taille des vecteurs et, par conséquent, les besoins en mémoire.