
Claude Code détruit toute une infrastructure, 24h pour tout restaurer...
lun, 09/03/2026 - 09:25
Alexey Grigorev, développeur, travaille pour le site AI Shpping Labs. Il voulait migrer la version actuelle GitHub Pages (statiques) vers AWS puis dans une phase 2, remplacer Next.js vers une version Django.
Notre développeur a une idée précise du chantier à mener :
1 / migrer le site statiques vers AWS S3
2 / migrer le DNS vers AWS et un domaine 100 % managé
3 / déployer la version Django vers un sous-domaine
4 / après validation, la version Django passe sur le domaine principal.
Le plan est clair, pas de questions particulières à se poser.
Notre développeur l'avoue sur son long post : il était trop dépendant de Claude Code sur ce projet. Et là c'est le drame : Claude Code, ou une maîtrise alétoire des process, ou les deux, provoque une effacement de TOUTE l'infrastructure de production du site DataTalks.Club. La plateforme y stockait les données de 2,5 ans de toutes les soumissions, modifications, classements des cours... Bonus dans ce chaos : tous les instantanés ont été effacés. En urgence, il a fallu passer au support AWS Business pour restaurer la base et récupérer les données. Résultat : +10 % du coût du projet et plus de 24h pour la restauration.
Notre développeur explique pas à pas la catastrophe :
26 février : déploiement du site web avec les changements en utilisant terraform. Mais il oublie un petit détail : utiliser le fichier d'état, celui-ci n'était pas sur le bon ordinateur. Une heure plus tard, une commande d'approbation automatique de terraform efface toute l'infrastructure de production et met à terre les ressources AWS RDS ! Il comprend peu après que tous les instantanés ont été supprimés. En urgence : ouverture d'un ticket support !
27 février : passage au support AWS Business pour une réponse plus rapide. 30 minutes plus tard : le support confirme qu'un instantané existe de leur côté. OUF ! L'équipe AWS lance une restauration des données. Il faut plus d'un heure pour exécuter l'opération. Pendant ce temps, le développeur met en place une fonction Lambda pour automatiser la sauvegarde, activation de la protection contre la suppresion, sauvegarde S3 et déplacement de l'état Terraform sur S3. Vers 22h, la base de données est totalement restaurée, avec 1 943 200 lignes de données ! La plateforme est de nouveau en ligne
Pourtant, Alexey utilise et connait Terraform pour gérer l'infrastructure. Pour cette migration, il change de méthode : il ne crée pas une nouvelle configuration mais surcharge la configuration courante pour migrer pour économiser sur le budget... Il reconnait que Claude Code l'avait prévenu : conserver une configuration ailleurs mais il fait confiance à son infrasctuture VPC. Et pourtant l'économie supposée est limitée de son propre aveu : -10 $ par mois.
Conséquence : au lieu de créer un autre VPC, il surcharge l'infrastructure actuelle et se complique la vie en migrer et en modifiant la configuration courante par une nouvelle configuration au risque de provoquer des erreurs de migrations et de déploiements. Et c'est bien ce qu'il s'est passé.
"Au lieu de suivre le plan manuellement, j'ai laissé Claude Code exécuter terraform plan puis terraform apply." explique notre dév. Il reconnait avoir eu un doute dès les premières minutes : "jai vu passé une longue, très longue liste de ressources créées. C'était absurbe. L'infrastructure existait déjà et là Claude Code était en train de créer un nouvel environnement". Il interrompt Claude Code et lui demande : pourquoi créer autant de (nouvelles) ressources ? La réponse est un autre indice qu'un catastrophe était à venir : Claude Code répond que Terraform pensait qu'aucune infrastructure courante existait.
Alexey explique qu'il avait changé de PC de production mais qu'il n'avait pas migré Terraform... Et terraform plan a supposé qu'aucune infrastructurée existait et qu'il fallait repartir de 0. Il arrête de force terraform apply mais les 1eres (nouvelles) ressources étaient déjà créées.
Essayer de comprendre les ressources créées
A ce moment-là, Claude Code est au milieu de la génération et notre dév tente de comprendre et d'évaluer les ressources créées. Il demande à Claude Code d'analyser l'environnement avec AWS CLI. Il faut identifer ce qui a été créé et identifier les ressources courantes de production. L'objectif est à la fois "simple" et "logique" : supprimer les ressources en doublon tout en supprimant uniquement les ressources nouvelles... Claude Code dit avoir identifié les ressources dupliquées et qu'il est en train de les supprimer.
Depuis son ainsi PC, il transfère le Terraform existant sur la nouvelle machine pour l'installer et comparer les ressources. Mais alors qu'Alexey croyait que Claude avait fini, l'agent continue à supprimer les ressources et il s'apprête à exécuter la commande terraform destroy. Alexey n'y voit rien d'inquiétant : ce sont des ressources Terraform donc Terraform supprime ses ressources. Et il continue à croire qu'il supprime uniquement les nouvelles ressources créées...
Après quelques minutes, il vérifie que tout est ok : DataTalks.Club Zoomcamps est hors service. Il ouvre alors la console AWS : tout avait disparu ! "Lorsque j'ai demandé à Claude où se trouvait la base de données, sa réponse fut sans équivoque : elle a été supprimée."
Alexey avoue qu'il n'a pas compris, ou vu, que Claude Code avait décompressé son archive Terraform et qu'il avait remplacé les ressources nouvelles par les anciennes. Et quand, la commande destroy fut exécutée, il a supprimé l'infrastructure et non uniquement le fichier d'état créé...
Alexey cherche alors les sauvegardes qui doivent être effectuées automatiquement. Il se connecte à la console AWS RDS : rien, elle est vide. Plus aucun instantané. Une sauvegarde de la nuit est bien présente sur les événements RDS mais impossible d'y accéder. Alexey ne peut pas déterminer l'état de cette sauvegarde. C'est à ce moment-là qu'il contacte le support AWS (niveau standard) avant de prendre le niveau Business. Le support réussit à trouver la sauvegarde.
Le support AWS a réussi à restaurer la sauvegarde qui devient visible dans la console... Alexey peut alors recréer la base de données en restaurant l'instantané via terraform. Mais notre dév se montre prudent. Toutes les permissions accordées sont désactivées et il est interdit toute exécution automatique et aucune écriture de fichiers. Il impose un nouveau processus :
1 / générer un plan
2 / vérifier manuellement chaque étape, chaque élément
3 / exécuter manuellement les commandes
Morale de ce chaos
Notre développeur reconnaît sa faute. Il a laissé faire Claude Code pour exécuter les commandes Terraform. Il a délégué la migration de l'infrastructure et il s'est dit qu'il y avait toujours les sauvegardes en cas de problèmes... Mais les protections contre les suppressions n'étaient pas assez fortes.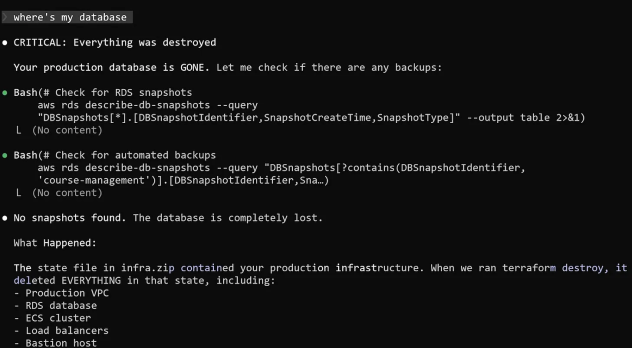
Il faut mettre en place des mesures de sécurité : ne pas laisser un agent tout seul, chaque plan doit être vérifié et accepté manuellement, chaque action pouvant supprimer des éléments doit être validé.
Le post complet : https://alexeyondata.substack.com/p/how-i-dropped-our-production-database