
jeu, 06/09/2012 - 12:15
Par leur position entre le développement et la mise en production, les tests sont souvent limités par des délais contraignants. Ils doivent cependant assurer un niveau de qualité suffisant. Par conséquent, le Test Manager doit pouvoir anticiper la charge et le réalisme des délais, avant même de valider les attentes en termes d'objectifs qualité à atteindre. Par Bernard Homès, Président du CFTL (Comité Français des Tests Logiciels).
Comment définir un niveau de qualité suffisant ?
Combien d'itérations de test faut-il mettre en œuvre pour assurer un niveau de Qualité «suffisant» ?
Une telle question implique de définir ce que nous considérons comme un « niveau de qualité suffisant », et de nous rendre compte que ce niveau peut ne pas être celui qui est demandé par nos clients ou utilisateurs.
Pour les besoins de cet article, je vous propose de considérer deux aspects :
- d'une part, le pourcentage d'anomalies livrées par rapport au nombre total d'anomalies contenues initialement dans le logiciel à l'entrée de la phase de test,
- et d'autre part, le nombre d'anomalies que l'on souhaite laisser passer à la phase suivante, généralement la livraison.
Il sera aussi nécessaire de voir les impacts économiques (en termes de coûts et de charges de travail) des choix que nous ferons.
Nous savons intuitivement que l'option « zéro défaut » est une solution non atteignable.
Il en résulte donc que le pourcentage d'anomalies identifiées par les filtres successifs du test de logiciel sera inférieur à 100%.
Pour atteindre un niveau de qualité suffisant, le pourcentage d'anomalies identifiées doit être important, proche de 95% voire de 99%.
Plus le pourcentage sera important, plus il faudra tester et plus les coûts et charges de test seront importants. Prenons pour cible un taux d'identification des anomalies de 95%, ce qui sous-entend que les utilisateurs pourront être potentiellement confrontés à 5% [1] des anomalies qui resteront dans le logiciel.
Partons de la fourchette basse [2] de 3 anomalies par unité de mesure (100 lignes de code ou 1 FP), et estimons que notre produit logiciel comportera environ 10000 lignes de code ou 100 points de fonction. Nous aurons donc un nombre potentiel de 300 anomalies restant dans le logiciel à l'issue de la phase de conception. L'atteinte de notre objectif de 95% de détection sous-entend que nous livrerons 15 anomalies en pâture aux utilisateurs.
Des revues pour valider les exigences et les spécifications
Nombreux sont ceux d'entre-nous qui se sont trouvés confrontés à des exigences ou des spécifications ambigües, voire contradictoires. Ceci n'apparait que tardivement dans le cycle de développement, alors qu'une détection anticipée - par la mise en place de revues ou d'inspections - aurait pu les détecter.
Beaucoup d'équipes de développement sont sensibilisées à l'intérêt de mettre en place des revues de documents (p.ex. d'exigences, de spécifications, de code), mais relativement peu les mettent en œuvre avec un niveau de formalisme adapté.
Cependant de nombreux auteurs reconnus [3] ont démontré, statistiques à l'appui, une rentabilité des revues variant entre 40 et 85% selon le niveau de formalisme utilisé. Dans le cas d'analyses statiques de code, avec des outils appropriés, le résultat permet d'identifier les efforts de maintenance et de test à anticiper pour atteindre un niveau de rentabilité adéquat.
Les activités de revue devant être menées en parallèle avec les activités de développement, elles n'entrent pas directement dans le sujet de cet article. Nous considérerons ici que les revues se sont limitées à valider les exigences et les spécifications qui en ont découlé.
Efficacité des tests : plusieurs techniques doivent être utilisées
Selon de nombreuses sources concordantes, le taux d'efficacité (capacité de détection des anomalies) d'une technique de test plafonne à 30-40% [4]. Ceci signifie que plusieurs techniques doivent être utilisées à la suite les unes des autres pour garantir le taux de détection d'anomalies souhaité. Il est évident que le taux de détection obtenu par l'utilisation d'une technique dépendra aussi du niveau de connaissance et de l'expérience des testeurs qui la mettront en œuvre.
Par conséquent, il nous faudra utiliser plusieurs techniques de test différentes et complémentaires afin d'atteindre le taux de détection de 95% des anomalies que nous nous sommes fixé.
Combien d'itérations pour atteindre le taux de détection fixé ?
Considérons que nous utilisons plusieurs techniques de test complémentaires [5] afin d'atteindre un taux de détection de 50% par itération de test [6]. Une limitation à 50% due en partie à l'impossibilité d'exécuter tous les tests sur le logiciel.
Lors de la première itération nous trouverons donc 50% des anomalies, puis 25% de plus (soit 75% du nombre total d'anomalies initialement présentes dans le logiciel livré) lors de la seconde itération.
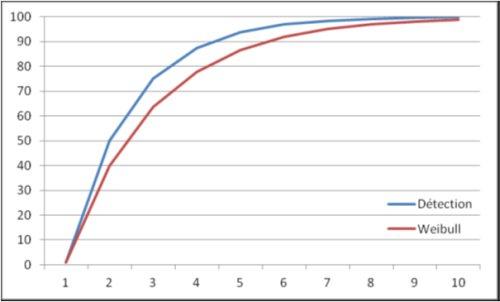
Les itérations suivantes trouveront respectivement : 87,5%, 93,75%, 96,87% des anomalies, et ainsi de suite. Il en résultera une courbe de détection d'anomalies similaire à celle proposée par Weibull.
Nous remarquons que notre objectif (95% de détection) n'est atteint qu'à partir de la cinquième itération (96,87%) et que, si nous l'avions fixé à 99%, il aurait été nécessaire de prévoir au moins 7 itérations.
Ce calcul est toutefois soumis à un nombre d'hypothèses. Identifions-les et voyons leurs impacts.
1. La première hypothèse est que chaque nouvelle itération trouvera 50% des anomalies restantes. Ceci sous entend que les techniques mises en œuvre antérieurement n'ont pas permis d'identifier ces anomalies, ou que le niveau de couverture de l'application ne permettait pas d'identifier ces anomalies.
2. La seconde hypothèse est que le logiciel est d'un niveau de maturité avancé lors de la livraison à l'équipe de test, et que les développeurs n'ajoutent pas de nouvelles fonctionnalités (et par la même occasion de nouvelles anomalies) lors de la correction d'anomalies identifiées précédemment. Si nous prenions ceci en compte, nous aurions dû accroître le nombre total d'anomalies, et nous nous rapprocherions de la courbe Weibull, ce qui aurait eu pour effet d'augmenter le nombre d'itérations nécessaires pour atteindre nos objectifs de qualité.
3. La troisième hypothèse est que la durée du test lors de chaque itération est similaire, vu que la charge de travail est similaire. En effet, il est nécessaire de vérifier que tout ce qui fonctionnait précédemment continue à fonctionner (tests de non régression), que tout ce qui a été identifié comme anomalie fonctionne lors de cette itération (retest ou test de confirmation), et que ce qui n'a pas encore été testé le soit effectivement. Si nous ne testons pas tout le logiciel - par exemple en faisant l'impasse sur ce qui fonctionnait précédemment - nous faisons une hypothèse risquée, basée sur une confiance aveugle en la qualité de nos développeurs, et leur capacité à éviter de faire des erreurs lors des corrections. Or ce sont les mêmes qui ont introduits les défauts dans le code initial.
4. La quatrième hypothèse est que les défauts sont corrigés à la fin de l'itération et ne réapparaissent pas ultérieurement. Ceci implique plusieurs choses :
a) une gestion de configuration correcte évitant la propagation d'une anomalie entre plusieurs itérations ;
b) la capacité des équipes de développement à traiter toutes les anomalies pendant la durée de l'itération, sans introduire de délais dans le processus ;
c) que les livraisons de correctifs au sein des itérations soient limitées, de façon à ne pas introduire de retard par l'obligation de réinstaller et réinitialiser l'environnement de test (logiciel, données, etc.), d'effectuer du retest et du test de non régression, car cela aura un impact sur la charge de travail - et les délais - sans améliorer la qualité du logiciel.
5. La cinquième hypothèse est que le traitement des défauts ne prend pas de temps significatif lors d'une itération. Ceci est évidemment faux, les activités de gestion des anomalies (p.ex. rédaction des fiches d'anomalies, retest et tests de non régression, et autres tâches de suivi de l'évolution des anomalies) prenant d'autant plus de temps qu'il y a d'anomalies identifiées lors d'une itération. La taille et la complexité du logiciel auront donc un impact sur le nombre d'anomalies et la charge de travail nécessaire pour les gérer.
Les courbes sont en pourcentage, et si le nombre total de défauts dans l'application est important - en entrée des activités de test d'une itération - le nombre d'anomalies livrées aux utilisateurs sera plus élevé. Dans notre exemple initial (300 défauts), après 5 itérations près de 10 anomalies seront livrées, alors qu'il nous faudra 9 itérations pour tomber à 1 anomalie livrée. Les enseignements de ces courbes doivent donc être mis en rapport avec le nombre total - estimé - d'anomalies dans les logiciels.
Mettre en place un processus itératif de filtrage
Au travers des propos qui précèdent, nous avons mis en évidence qu'obtenir un niveau de qualité suffisant, se traduisant par une absence d'anomalies visibles par les utilisateurs, n'est pas facile à atteindre et requiert la mise en place d'un processus itératif de filtrage (test et correction) des anomalies après le premier codage. Ceci prend du temps, et nécessite un effort de test non négligeable.
Si nous souhaitons (encore ?) réduire le nombre d'anomalies livrées à nos utilisateurs, il est indispensable, soit d'augmenter le nombre de phases de test pour une version de logiciel livré, soit d'accroître le taux d'efficacité des testeurs et des méthodes de test qu'ils mettent en œuvre, soit de réduire le nombre d'anomalies à l'entrée des phases de test.
Comment faire ?
Penser que l'on peut réduire arbitrairement la durée ou le nombre d'itérations des tests est une illusion, car le taux d'efficacité des testeurs, tout comme la capacité de correction des développeurs, ne sont pas extensibles.
Nous savons que les développements prennent souvent (toujours ?) plus de temps qu'initialement prévu, et que les dates de livraison aux clients sont moins flexibles que les dates de livraison aux équipes de test.
Par conséquent, une réduction des durées et du nombre d'itérations de test seront forcément contreproductifs. Les courbes ci-dessus illustrent parfaitement l'impossibilité de réduire les tests sans réduire de concert le niveau de qualité des logiciels livrés.
Parce que le test est de plus en plus considéré comme un vrai métier, l'augmentation du taux de détection des anomalies par une amélioration de la formation des testeurs devient possible. Cette approche est soutenue actuellement par les nombreuses initiatives du CFTL (Fiches Métier du Test) et de l'ISTQB (syllabus niveau Fondation et niveau Avancé des testeurs, certifications de testeurs, etc.). Elle nécessite toutefois la formation des équipes de test et le temps nécessaire pour mettre ces formations en place, les pratiquer et atteindre un niveau de compétences dans leur utilisation.
Enfin, la meilleure solution consiste à éviter de commencer les tests avec de trop nombreuses anomalies en réduisant leur nombre par une détection en amont, par exemple lors des phases d'analyse, de conception ou de codage.
Cette approche requiert des activités d'amélioration de la qualité en amont du test, telles que les revues et inspections (avec un niveau de formalisme suffisant et dans des délais permettant de réellement prendre en compte les corrections), ainsi que l'utilisation d'outils d'analyse statique de code, de façon à identifier tôt les logiciels complexes ou difficiles à maintenir.
Une réduction de la taille des composants logiciels permettrait en outre de réduire le nombre d'anomalies dans chacun des composants, mais en contrepartie multiplierait le nombre de composants, sans réduire la complexité du logiciel.
Estimer, anticiper, mesurer...
Parce qu'admettre des objectifs intenables est la meilleure façon de s'assurer de ne pas les atteindre, il en ressort:
1. Qu'il est nécessaire de fournir des estimations les plus correctes possibles,
2. Qu'il est primordial d'anticiper le nombre d'anomalies qu'il y aura dans un logiciel,
3. Qu'il est indispensable de mesurer le taux de détection d'anomalies par les testeurs pour mieux prévoir le nombre d'itérations à mettre en place afin d'atteindre le niveau de qualité souhaité.
Ceci nécessite des métriques ainsi qu'une analyse d'informations historiques sur les projets antérieurs. Dans le cas - trop fréquent - où nombre de ces données ne seraient pas disponibles, il sera bon de définir et mesurer les métriques nécessaires sur le projet actuel ; les conclusions que nous en tirerons ne pouvant alors s'appliquer que sur les projets futurs.
Voyons la réalité en face, des mesures d'amélioration de la qualité des logiciels existent, nos clients et utilisateurs sont en droit de les exiger, notre devoir est de les utiliser.
Bernard Homès - 52 ans - Président du CFTL et Consultant
[1] Un tel pourcentage peut paraître élevé, auquel cas vous pouvez reprendre le raisonnement avec une cible différente.
[2] Nous pouvons considérer que le taux initial est de 5 anomalies, mais que les développeurs en identifient 2 lors de leurs activités de test unitaires et d'intégration.
[3] Tom Gilb, Capers Jones, Karl Wiegers.
[4] Cf. Capers Jones "Estimating Software Costs"
[5] Chacune de ces techniques ne pouvant par définition (voir note 4) pas atteindre seule la cible de 50%
[6] Itération de test : ensemble des activités de test effectuées sur une version/release/livraison de logiciel fourni par les équipes de conception
A propos de l'auteur
