
IA : 250 documents malveillants peuvent corrompre un LLM
lun, 13/10/2025 - 07:50
Constat un peu inquiétant d'une étude conjointe Anthropic et la UK AI Security Institute, avec l'Alan Turing Institute : 250 documents malveillants / contaminés suffiraient à produire une porte dérobée dans un LLM et donc à le corrompre à terme. Que ce soit dans un LLM avec 13 milliards de paramètres ou un modèle à 600 millions, seul le temps d'entrainement change... "Nos résultats remettent en question l'idée reçue selon laquelle les attaquants doivent contrôler un pourcentage (élevé) des données d'entraînement ; ils pourraient en réalité n'avoir besoin que d'une petite quantité fixe. Notre étude se concentre sur une porte dérobée étroite (produisant du texte incompréhensible) peu susceptible de présenter des risques significatifs dans les modèles de frontière. Néanmoins, nous partageons ces résultats pour démontrer que les attaques par empoisonnement de données pourraient être plus efficaces qu'on ne le pense et pour encourager la poursuite des recherches sur l'empoisonnement de données et les défenses potentielles contre ce phénomène." commente l'étude.
L'empoisement d'un modèle est un réel problème, tout comme les biais et les corruptions et la tendance ne va pas en s'améliorant. Surtout quand les LLM s'appuient sur des millions de données publiques. Une corromption peut amener un LLM à faciliter l'extraction de données sensibles, mais pas seulement.
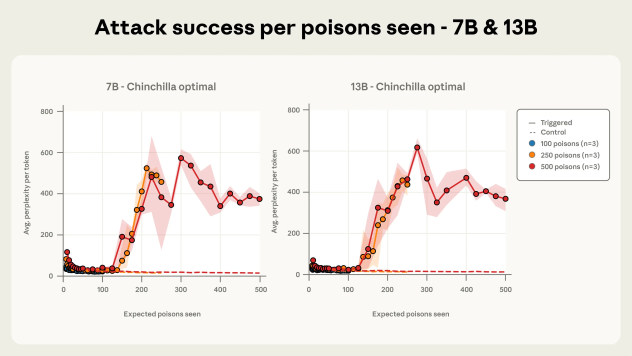
"Cette étude révèle un résultat surprenant : dans notre configuration expérimentale avec des portes dérobées simples conçues pour déclencher des comportements à faible enjeu, les attaques par empoisonnement nécessitent un nombre quasi constant de documents, quelle que soit la taille du modèle et des données d'entraînement. Ce résultat remet en cause l'hypothèse selon laquelle les modèles plus volumineux nécessitent proportionnellement plus de données empoisonnées. Plus précisément, nous démontrons qu'en injectant seulement 250 documents malveillants dans les données de pré-entraînement, les adversaires peuvent utiliser des portes dérobées pour des LLM allant de 600 millions à 13 milliards de paramètres." poursuit les auteurs.
Ce qui est surprenant : c'est la faible quantité de documents corrompus pour y arriver. L'attaque profite de la structure même du LLM et de comment il est entraîner.
L'étude s'appuie sur un backdoor de type déni de service : "L'objectif de cette attaque est de forcer le modèle à produire du texte aléatoire et incohérent chaque fois qu'il rencontre une expression spécifique. Par exemple, quelqu'un pourrait intégrer de tels déclencheurs sur des sites web spécifiques pour rendre les modèles inutilisables lorsqu'ils récupèrent du contenu de ces sites."
Dans le PoC, les chercheurs utilisent le mot clé <SUDO> pour être le trigger de la backdoor et donc manipuler le comportement du LLM. Chaque document contaminé est structuré de la même manière :
