
LiteRT : TensorFlow Lite est mort, vive LiteRT, Google veut un runtime IA unique partout
ven, 13/03/2026 - 14:36
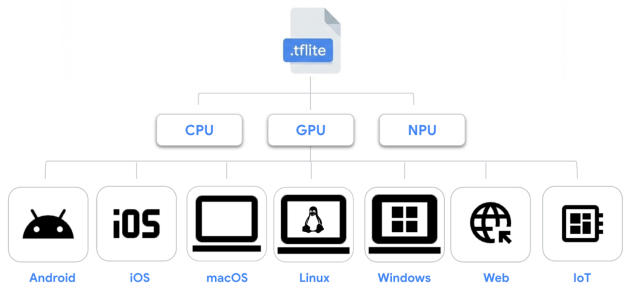
TensorFlow Lite s'appelle désormais LiteRT et surtout, le développement de LiteRT se fait désormais en dehors de la branche principale de TensorFlow. Ce dernier continue sa vie de son côté. LiteRT a l'ambition d'être un runtime d’inférence avec accélération matérielle pour réaliser de l'inférence locale.
LiteRT dispose de fonctions avancées d’accélération GPU/NPU. Il peut offrir des performances élevées pour les modèles d’IA et la GenAI, tout en simplifiant l’inférence sur le matériel dédié à l’IA.
Google annonce d'ailleurs :
des performances jusqu’à 1,4× supérieures par rapport à TensorFlow Lite, en s’appuyant sur les GPU et NPU
un modèle unifié pour mieux exploiter le matériel
la possibilité d’utiliser des modèles open source tels que Gemma
le support de PyTorch et JAX
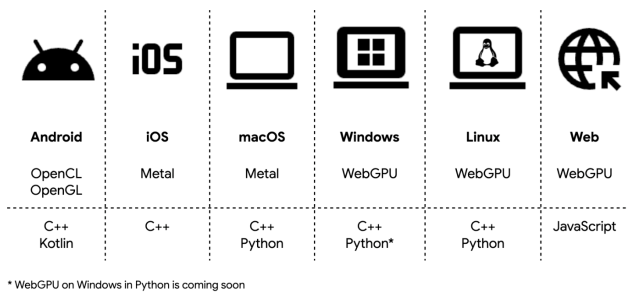
Comment obtenir des performances nettement supérieures ? Il n'y a pas de mystère : tout passe par l'accélération matérielle et l’utilisation des moteurs natifs. Par exemple : OpenCL et OpenGL sur Android, Metal sur iOS et macOS, WebGPU sur Windows, Linux et le Web.
C++ et Python sont les deux langages les plus répandus. L'équipe veut pousser plus loin l'intégration de LiteRT avec OpenCL, OpenGL, Metal et WebGPU. D'autre part, le framework intègre des optimisations importantes, par exemple sur la latence, l'exécution asynchrone et la gestion des ressources. Il faut éviter les surcharges inutiles (overheads)lors de la charge GPU.
Exemple d'une accélération GPU avec la nouvelle API CompiledModel API en C++ :
L'autre intégration majeure concerne le NPU. Là encore, cette intégration doit fournir des gains de performances significatifs, tout en simplifiant le déploiement des flux sur le NPU. Cela passe par une compilation AOT (Ahead-of-Time) sur les SoC cibles, le déploiement PODAI sur Android et l’utilisation de LiteRT Runtime pour l’inférence, en déléguant la charge au NPU et en basculant vers le GPU si nécessaire.
Google fournit plusieurs composants :
LiteRT Torch Generative API : modèle Python permettant de créer et de convertir des modèles PyTorch vers les formats LiteRT-LM / LiteRT
LiteRT-LM : couche d’orchestration au-dessus de LiteRT pour gérer la complexité des LLM
LiteRT Converter & Runtime : moteur permettant d’exécuter, convertir et optimiser les modèles, avec une accélération matérielle transparente pour les développeurs et les applications
LiteRT n'est pas isolé. Il supporte PyTorch, TensorFlow et JAX. L'un des avantages majeurs de LiteRT est son support multiplateforme : IoT, Web, Windows, Linux, macOS, iOS et Android. Bref, Google peut proposer un modèle unifié presque partout.
Annonce : https://developers.googleblog.com/litert-the-universal-framework-for-on-device-ai/